
今日下午,谷歌AlphaGo在人机对战的第一盘战胜李世石。相关消息刷爆社交媒体,虽然李世石赛前曾经表示,人工智能击败人类长期来看将是不可避免的事,这次他将坚决为捍卫人类尊严而战,但他还是出现了几个失误,输给了AlphaGo。这个战胜李世石的“阿法狗”究竟是何方神圣?
如果不对 AlphaGo 背后的神经网络系统稍作了解,你很容易以为 AlphaGo,在对局开始前跟李世石站在同一起跑线上。
作为一种人工智能的 AlphaGo,和 IBM 在上个世纪打败国际象棋大师卡斯帕罗夫的深蓝超级计算机,以及当代的苹果 Siri、Google Now 有着显著的区别。
要了解 AlphaGo,首先我们需要了解 AlphaGo 背后到底是一个什么东西。
它背后是一套神经网络系统,由 Google 2014 年收购的英国人工智能公司 DeepMind 开发。这个系统和深蓝不同,不是一台超级计算机,而是一个由许多个数据中心作为节点相连,每个节点内有着多台超级计算机的神经网络系统。就像人脑,是由 50-100 亿个神经元所组成的,这也是为什么这种机器学习架构被称为神经网络。
你可以将 AlphaGo 理解为《超验骇客》(Transcendence) 里约翰尼·德普饰演的人工智能,而它所控制的超级计算机,就像影片里被人工智能心控的人类一样,共同为一种蜂群思维 (Hive Mind) 服务。
《超验骇客》中,被人工智能控制的工人马丁。马丁没有所想,但他的所见将会被人工智能直接获取

AlphaGo 是在这个神经网络系统上,专为下围棋 (Go) 而开发出的一个实例。然而,虽然名字已经介绍了它的功能,AlphaGo 背后的神经网络系统却适合用于任何智力竞技类项目。
这个系统的基础名叫卷积神经网络 (Convolutional Neural Network, CNN) ,这是一种过去在大型图像处理上有着优秀表现的神经网络,经常被用于人工智能图像识别,比如 Google 的图片搜索、百度的识图功能都对卷积神经网络有所运用。这也解释了为什么 AlphaGo 是基于卷积神经网络的,毕竟围棋里胜利的原理是:
对弈双方在棋盘网格的交叉点上交替放置黑色和白色的棋子。落子完毕后,棋子不能移动。对弈過程中围地吃子,以所围“地”的大小决定胜负。

AlphaGo Logo / DeepMind
AlphaGo 背后的系统还借鉴了一种名为深度强化学习 (Deep Q-Learning, DQN) 的技巧。强化学习的灵感来源于心理学中的行为主义理论,即有机体如何在环境给予的奖励或惩罚的刺激下,逐步形成对刺激的预期,产生能获得最大利益的习惯性行为。不仅如此,AlphaAlphaGo 还在判断当前局面的效用函数 (value function) 和决定下一步的策略函数 (policy function) 上有着非常好的表现,远超过上一个能够和人类棋手旗鼓相当的围棋程序蒙特卡洛 (Monte Carlo Tree Search 算法)。
AlphaGo 所采用的 DQN 是一种具有广泛适应性的强化学习模型,说白了就是不用修改代码,你让它下围棋它能下围棋,你让它在红白机上玩超级玛丽和太空侵略者,它也不会手生。作为一个基于卷积神经网络、采用了强化学习模型的人工智能,AlphaGo 的学习能力很强,往往新上手一个项目,玩上几局就能获得比世界上最厉害的选手还强的实力。
2014 年,已经被 Google 收购的 DeepMind,用五款雅达利 (Atari) 游戏 Pong、打砖块、太空侵略者、海底救人、Beam Rider 分别测试了自己开发的人工智能的性能,结果发现:在两三盘游戏后,神经网络的操控能力已经远超世界上任何一位已知的游戏高手。
DeepMind 用同样的一套人工智能,不调整代码就去测试各种各样的智力竞技项目,取得了优异的战绩,足以证明今天坐在李世石面前的 AlphaGo ,拥有多强的学习能力。

李世石执黑子,AlphaGo 执白子。大约进行了 85 分钟时进入休息阶段。
在此之前,DeepMind 进行过的无数虚拟棋局训练,以及去年击败欧洲围棋冠军樊麾二段的经验让 AlphaGo 已经训练出了顶尖的弈技,极有可能高于世界上任何已知的围棋高手。
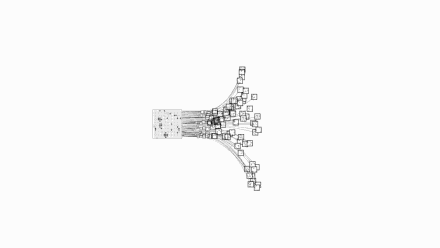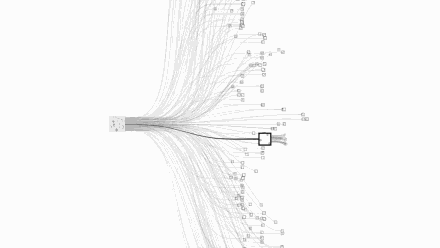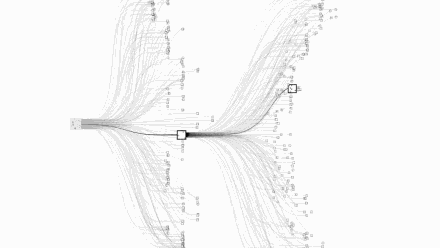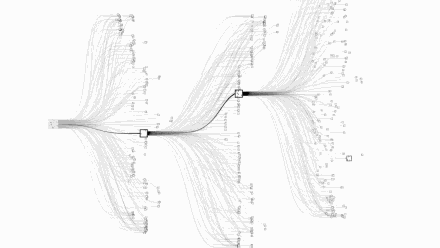
围棋的可能性复杂度
尽管棋盘上风云变化,早在本次开战前,AlphaGo 跟李世石就已不在同一起跑线上了。至于李世石曾经做出 AlphaGo 和自己棋份在二子和让先之间的评论,恐怕第一局足够让他反悔了。
AlphaGo 只是 DeepMind 证明自己的一个工具。你也可以将这次和李世石的对局理解为 Google 的公关策略。
2014 年,这家公司曾经在其官网上写道: DeepMind 致力于用研究深度学习的方式去真正了解智慧 (solve intelligence) 。但对于 DeepMind 和 Google 来说,打造 AlphaGo 以及其他人工智能神经网络不是终点。

DeepMind 三位联合创始人
将机器学习和神经科学进行结合,打造出一种“一般用途的学习算法”。通过这种算法,DeepMind 和 Google 希望能够将智能“定型化”,理解智能是什么,进而更好的帮助人类理解大脑。DeepMind 联合创始人之一的 Demis Hassabis 曾经写道:
用算法将智慧提炼出来,有可能成为理解人类思维最神秘原理的最佳方式。
attempting to distil intelligence into an algorithmic construct may prove to be the best path to understanding some of the enduring mysteries of our minds.
在 Google 收购 DeepMind 前,收购条款中的一项就是 Google 必须成立人工智能道德委员会。因此,在目前阶段人们不必担心这样的人工智能最终杀死或统治人类。但至少,人工智能在围棋这样的智力类竞技项目上击败人类,是已经注定的事情。
作为一种决策树巨大的游戏,围棋本来适合人脑思考,不适合机器运算。但 DeepMind AI 的方向就是模仿人脑思考,用神经网络“重现”智慧。
本文转载自“PingWest品玩”,作者:光谱,新媒已获得授权。
你怎么看这场比赛?欢迎后台“勾搭”小新~